Research
Training on Analog In-memory Computing Hardware
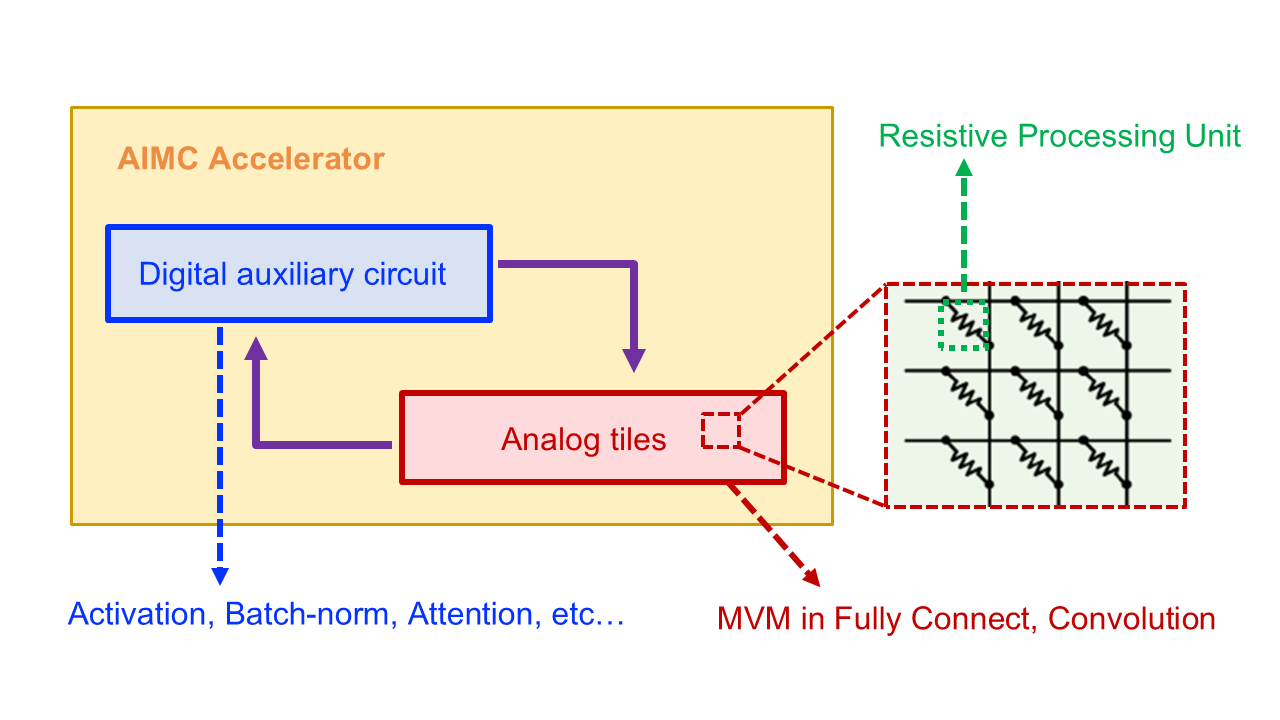
Modern deep model training often requires processing vast amounts of weights and data, which necessitates frequent data transfer between memory and processor, leading to the "von Neumann bottleneck" that can significantly hinder computation speed and efficiency. In this context, Analog in-memory computing (AIMC) is an innovative computing paradigm that utilizes the physical properties of emerging Resistive Processing Unit (RPU) devices to perform computations directly within the memory array. Its core principle is to harness the analog storage and processing capabilities of these devices—leveraging the physical laws of Ohm and Kirchhoff—to execute Matrix-Vector Multiplication (MVM) operations in a highly parallel and energy-efficient manner.
To fully realize the massive parallelism and energy efficiency benefits of AIMC, it is essential to perform the fully on-chip training process of Deep Neural Networks (DNNs) directly on the AIMC hardware. However, this ambitious goal faces significant challenges stemming from the inherent non-idealities of analog hardware. Key difficulties include the non-linear response of RPU devices, the pervasive presence of analog noise during computation, and the limited precision inherent in analog operations. Achieving the high accuracy required for training deep models, especially given these imperfections, remains a formidable obstacle.
Crucially, since these hardware imperfections, such as device non-linearities and analog noise, are fundamentally physical and cannot be entirely eliminated in the foreseeable future, algorithmic solutions become essential. To address this reality, my research focuses on developing novel algorithms and techniques that enable the effective training of DNNs on AIMC hardware. Our core objective is to establish a robust training paradigm that enables deep learning models to seamlessly "coexist" with the intrinsic imperfections of analog accelerators. Specifically, we aim to develop algorithms that are inherently robust against hardware imperfections, ultimately bridging the gap between the computational demands of DNNs and the realities of non-ideal analog in-memory accelerators.
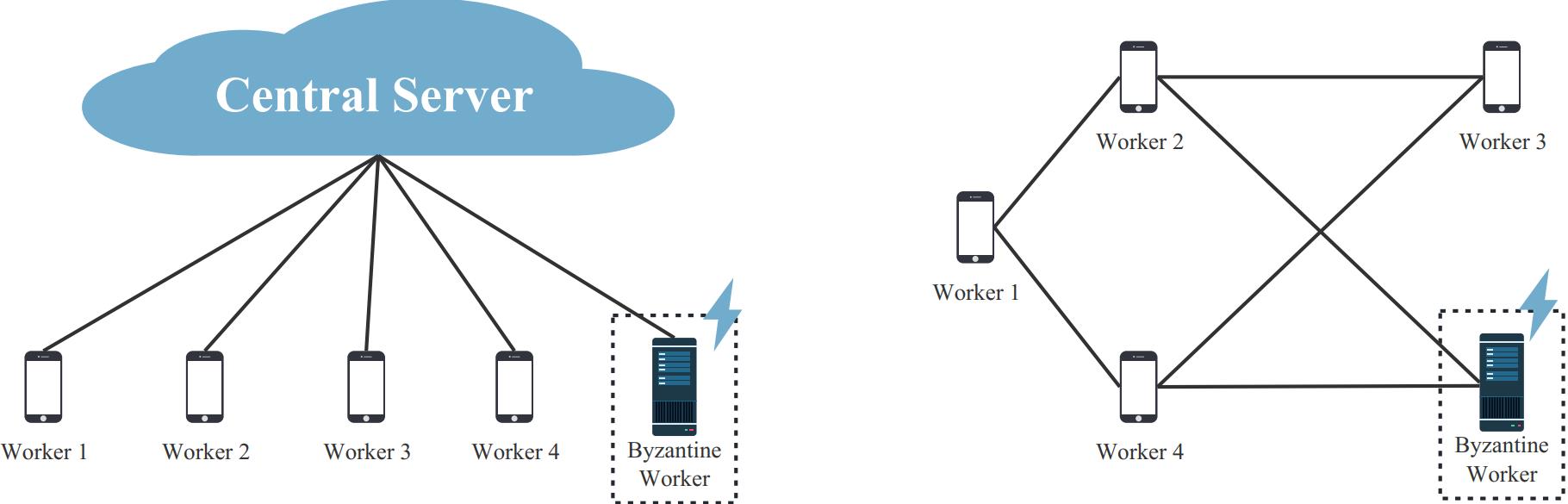
Distributed Optimization
Distributed or decentralized learning, which involves a series of single devices (workers) collaborating to train a machine learning model, usually serves as a promising solution in the following scenarios:- Accelerate large-scale machine learning through parallel computation in data centers.
- Exploit the potential value of large-volume, heterogeneous, and privacy-sensitive data located at geographically distributed devices in settings like federated learning (FL) or multi-agent reinforcement learning (MARL).
Journals
On the Trade-Off Between Flatness and Optimization in Distributed Learning
Ying Cao, Zhaoxian Wu, Kun Yuan, Ali H. Sayed
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
-
Yue Huang, Zhaoxian Wu, Shiqian Ma, Qing Ling
IEEE Transactions on Signal Processing (TSP), 2025
-
Xingrong Dong, Zhaoxian Wu, Qing Ling, Zhi Tian
IEEE Transactions on Signal Processing (TSP), 2024
Byzantine-Resilient Decentralized Stochastic Optimization with Robust Aggregation Rules
Zhaoxian Wu, Tianyi Chen, Qing Ling
IEEE Transactions on Signal Processing (TSP), 2023
Byzantine-Robust Variance-Reduced Federated Learning over Distributed Non-i.i.d. Data
Jie Peng, Zhaoxian Wu, Qing Ling
Information Sciences, 2022
Communication-censored Distributed Stochastic Gradient Descent
Weiyu Li, Zhaoxian Wu, Tianyi Chen, Liping Li, Qing Ling
IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2021
Byzantine-resilient Decentralized Policy Evaluation with Linear Function Approximation
Zhaoxian Wu, Han Shen, Tianyi Chen, Qing Ling
IEEE Transactions on Signal Processing (TSP), 2021
Federated Variance-reduced Stochastic Gradient Descent with Robustness to Byzantine Attacks
Zhaoxian Wu, Qing Ling, Tianyi Chen, and Georgios B Giannakis
IEEE Transactions on Signal Processing (TSP), 2020
Conference
Analog In-memory Training on General Non-ideal Resistive Elements: The Impact of Response Functions
Zhaoxian Wu, Quan Xiao, Tayfun Gokmen, Omobayode Fagbohungbe, Tianyi Chen
Conference on Neural Information Processing Systems (NeurIPS), 2025
Towards Exact Gradient-based Training on Analog In-memory Computing
Zhaoxian Wu, Tayfun Gokmen, Malte J. Rasch, Tianyi Chen
Conference on Neural Information Processing Systems (NeurIPS), 2024
-
Yue Huang, Zhaoxian Wu, Qing Ling
International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2024
Distributed Online Learning With Adversarial Participants In An Adversarial Environment
Xingrong Dong, Zhaoxian Wu, Qing Ling, Zhi Tian
International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2023
A Byzantine-resilient Dual Subgradient Method for Vertical Federated Learning
Kun Yuan, Zhaoxian Wu, Qing Ling
International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2022
Byzantine-resilient Decentralized TD Learning with Linear Function Approximation
Zhaoxian Wu, Han Shen, Tianyi Chen, Qing Ling
International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2021
Byzantine-resilient Distributed Finite-sum Optimization over Networks
Zhaoxian Wu, Qing Ling, Tianyi Chen, and Georgios B Giannakis
International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2020